REVEALED: Rubin - Everything We Know
На прошедшей в этом году конференции GTC генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) сообщил, что в этом году платформа Vera Rubin получит расширение. Nvidia использует для этого интеллектуальную собственность, приобретённую у Groq. В состав Rubin вошёл новый чип Nvidia Groq 3 LPU. Компания определяет его как ускоритель инференса. Его задача — выдавать токены в большом объёме и с низкой задержкой.








Источник изображений: Nvidia
Платформа Rubin уже включает шесть компонентов, из которых Nvidia собирает стоечные системы и затем масштабирует их до ИИ-фабрик. Это GPU Rubin, CPU Vera, коммутаторы внутрисистемного масштабирования NVLink 6, интеллектуальный сетевой адаптер ConnectX-9, процессор обработки данных BlueField-4 и коммутатор межсистемного масштабирования Spectrum-X с совместно интегрированной оптикой. Groq 3 LPU стал новым элементом этой платформы и ещё одним строительным блоком Rubin при масштабном развёртывании.

Groq 3 LPU отличается от большинства ИИ-ускорителей схемой памяти. Обычно такие системы используют HBM в качестве рабочего уровня памяти. Каждый Groq 3 LPU содержит 500 Мбайт SRAM. Для сравнения, каждый GPU Rubin оснащён 288 Гбайт HBM4. По ёмкости разница велика. По пропускной способности соотношение иное: SRAM обеспечивает до 150 Тбайт/с, а HBM4 — около 22 Тбайт/с. Для ИИ-задач, чувствительных к пропускной способности, рост этого показателя даёт преимущество при инференсе. Именно поэтому Nvidia вводит Groq 3 в состав Rubin.

Стойка Groq 3 LPX включает 256 чипов Groq 3 LPU. Такая система располагает 128 Гбайт SRAM. Её суммарная пропускная способность достигает 40 Пбайт/с. Для объединения чипов внутри стойки предусмотрен выделенный интерфейс внутрисистемного масштабирования. Его пропускная способность составляет 640 Тбайт/с на стойку.

Вице-президент Nvidia по гипермасштабируемым решениям Иэн Бак (Ian Buck) назвал Groq LPX сопроцессором для Rubin. По его словам, он повысит производительность декодирования «на каждом слое ИИ-модели на каждом токене». Nvidia связывает это решение со следующим рубежом ИИ — мультиагентными системами. Речь идёт о сценариях, где нужно обеспечивать интерактивную работу при инференсе моделей с триллионами параметров и окнами контекста в миллионы токенов.

Когда ИИ-агенты всё чаще обмениваются данными друг с другом, а не с человеком в окне чат-бота, меняется и порог приемлемого отклика. Скорость, достаточная для человека, оказывается слишком низкой для ИИ-агента. Бак описывает переход от мира, где разумным считался уровень 100 токенов в секунду, к уровню 1 500 токенов в секунду и выше для межагентного обмена.

Добавление Groq 3 LPU должно усилить позиции Rubin в сегменте низколатентного инференса. В тексте в качестве конкурента названа Cerebras. Компания использует процессоры Wafer-Scale Engine (WSE), выполненные на целой кремниевой пластине, где большие объёмы SRAM объединены с вычислениями для низколатентного инференса на продвинутых моделях. OpenAI также привлекала мощности Cerebras для обслуживания части передовых моделей из-за выгодных характеристик задержки этой платформы.

Иэн Бак также допустил, что появление Groq 3 LPU может сократить роль ускорителя инференса Rubin CPX. Он сказал, что сейчас Nvidia сосредоточена на интеграции стойки Groq 3 LPX с Rubin. Дополнительных подробностей он не привёл. При этом оба чипа рассчитаны на сходное усиление инференса, но Groq LPU не требует большого объёма памяти GDDR7, который нужен каждому модулю Rubin CPX.
Micron запустила массовое производство памяти HBM4 для Nvidia Vera Rubin
Поскольку на этой неделе Nvidia официально представила свою ИИ-платформу Vera Rubin, компания Micron Technology не нашла причин для дальнейшего сокрытия факта сотрудничества с ней в области поставок памяти типа HBM4. Было объявлено, что этот третий по счёту поставщик приступил к серийному производству микросхем HBM4 в 12-ярусном исполнении.

Источник изображения: Micron Technology
В одном стеке HBM4 при такой компоновке содержится 36 Гбайт памяти, которая способна передавать информацию со скоростью более 1 Гбит/с на контакт, обеспечивая совокупную пропускную способность на уровне 2,8 Тбайт/с. По сравнению с HBM3E той же марки, это соответствует росту пропускной способности в 2,3 раза и улучшению энергетической эффективности более чем на 20 %, как отмечает Tom’s Hardware. Micron Technology также отправила своим клиентам образцы 16-ярусных чипов HBM4 объёмом 48 Гбайт. По сравнению с 12-ярусным стеком, они обеспечивают увеличение удельной ёмкости на 33 %.
Одновременно Micron объявила о начале массового производства твердотельных накопителей семейства 9650, обеспечивающих поддержку новейшего интерфейса PCI Express 6.0. Данные накопители обеспечивают скорость последовательного чтения до 28 Гбайт/с и 5,5 млн операций ввода-вывода в секунду на операциях произвольного чтения. По сравнению с накопителями, оснащаемыми интерфейсом PCI Express 5.0, это обеспечивает вдвое более высокое быстродействие на операциях чтения, энергоэффективность также увеличивается в два раза. Данные накопители оптимизированы для использования в составе стоек BlueField-4 STX, относящихся к платформе Vera Rubin.
Кроме того, Micron представила модули памяти типа SOCAMM2 объёмом 192 Гбайт, также оптимизированные для решений Nvidia семейства Vera Rubin, включая стойки NVL72 и обособленные платформы на основе центральных процессоров Vera. Эти модули памяти будут предлагаться в диапазоне ёмкостей от 48 до 256 Гбайт. Платформа Vera Rubin поддерживает до 2 Тбайт оперативной памяти, а пропускная способность на один процессор достигает 1,2 Тбайт/с при использовании данной памяти. Все три новинки Micron уже производятся серийно и могут поставляться для нужд Nvidia и её партнёров, выпускающих решения семейства Vera Rubin.
Nvidia показала полный стек Vera Rubin — от GPU до сетей для ИИ-фабрик нового поколения
Являясь одним из лидеров в сфере вычислительной инфраструктуры для систем искусственного интеллекта, Nvidia комплексно подходит к развитию собственных платформ, а потому вместе с ускорителями поколения Vera Rubin предложила ряд сопутствующих аппаратных решений.

Источник изображений: Nvidia
Как отмечается в корпоративном пресс-релизе, платформа Vera Rubin открывает новые рубежи в развитии агентского искусственного интеллекта. В массовом производстве сейчас находятся семь новых чипов Nvidia, позволяющих эффективно масштабировать так называемые ИИ-фабрики. В число семи аппаратных новинок Nvidia вошли графические процессоры Rubin, центральные процессоры Vera, коммутаторы NVLink 6, сетевые решения ConnectX-9 SuperNIC, специализированные процессоры BlueField-4 и Ethernet-коммутаторы Spectrum-6, а также созданные с помощью разработок одноимённого поглощённого стартапа процессоры Groq для ускорения инференса при работе с ИИ-агентами. В совокупности они работают, как ИИ-суперкомпьютер, как отмечается в материалах Nvidia для прессы на официальном сайте компании, позволяя ускорять создание профильных технологий на всех этапах жизненного цикла ИИ-систем.
Основатель и глава Nvidia Дженсен Хуанг (Jensen Huang) заявил, что с выходом платформы Vera Rubin наступил переломный момент в развитии агентского ИИ, поскольку данная платформа будет способствовать самому масштабному развёртыванию инфраструктуры в истории. Руководители OpenAI и Anthropic прокомментировали анонс Vera Rubin в предсказуемо хвалебных выражениях, подчёркивая значение этого события для всей ИИ-отрасли. Разработчики ИИ-моделей теперь смогут совершенствовать их и делать это быстрее, чем на аппаратных решениях прошлого поколения.
Структура ЦОД теперь строится на готовых модулях, как считают в Nvidia, которые содержат всё необходимое для эффективного масштабирования вычислительных мощностей с учётом постоянного роста сложности решаемых задач. Клиенты могут сочетать готовые модули ЦОД с учётом специфики своей деятельности. Например, в одной стойке Vera Rubin NVL72 находятся 72 графических процессора Rubin и 36 центральных процессоров Vera, соединённых скоростной шиной NVLink 6 и сетевыми контроллерами ConnectX-9 SuperNIC, а также специализированные процессоры BlueField-4, которые разгружают центральные процессоры от задач работы с сетевым трафиком. По сравнению с решениями поколения Blackwell новые системы Vera Rubin справляются с обучением сложных моделей силами в четыре раза меньшего количества GPU. Пропускная способность в пересчёте на ватт потребляемой энергии в задачах инференса у Vera Rubin до десяти раз выше, а затраты на один токен в десять раз ниже. В кластерах стойки NVL72 масштабируются при помощи Quantum-X800 InfiniBand и Spectrum-X Ethernet.
Центральные процессоры Vera, по словам представителей Nvidia, хорошо себя проявляют в задачах обучения с подкреплением и агентских ИИ-нагрузках. Компания может объединять в одной стойке до 256 таких процессоров, оснащённых системой жидкостного охлаждения. С прочими компонентами кластера они могут сообщаться при помощи сетевых решений Spectrum-X. По сравнению с некими традиционными CPU, на которые ссылается Nvidia, её процессоры Vera могут справляться с ИИ-задачами на 50 % быстрее.

Специализированные чипы Groq 3 LPX обеспечивают эффективную работу с агентскими ИИ-нагрузками при минимальных задержках. В сочетании с другими чипами, входящими в состав платформы Vera Rubin, они обеспечивают увеличение пропускной способности в задачах инференса до 35 раз на один мегаватт потребляемой мощности, а потенциал выручки при использовании моделей с триллионом параметров увеличивается в десять раз. В состав одной стойки входит 256 чипов LPU, 128 Гбайт интегрированной на них памяти SRAM, а пропускная способность достигает 640 Тбайт/с. В сочетании с прочими компонентами платформы Vera Rubin, чипы LPU достигают максимальной эффективности как по быстродействию, так и по энергопотреблению, а также использованию ресурсов памяти. Стойки LPX будут доступны клиентам Nvidia со второй половины текущего года.
Стойка BlueField-4 STX специализируется на унификации адресного пространства GPU между элементами кластера. Обработка хранимой в кеше информации в операциях инференса ускоряется до пяти раз, при этом обеспечивается высокая энергоэффективность по сравнению с системами на классической архитектуре. Достигается общий для кластера контекст, обеспечивающий быстрое взаимодействие с ИИ-агентами и более эффективно масштабируемыми ИИ-сервисами.
Отдельная стойка Spectrum-6 SPX отвечает за скоростной обмен данными по интерфейсу Ethernet. Она может содержать не только коммутаторы Spectrum-X Ethernet, но и коммутаторы Nvidia Quantum-X800 InfiniBand в зависимости от потребностей конкретной конфигурации. В исполнении с кремниевой фотоникой и интеграцией на уровне упаковки чипов эффективность передачи информации возрастает в пять раз, а надёжность по сравнению с традиционными подключаемыми решениями увеличивается в десять раз.
«Космические вычисления уже здесь»: Nvidia представила модуль Space-1 Vera Rubin для орбитальных ИИ-серверов
Генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) анонсировал на конференции GTC 2026 космический модуль Nvidia Space-1 Vera Rubin Module. По словам Хуанга, модуль обеспечивает до 25 раз большую вычислительную мощность для задач искусственного интеллекта, чем сервер с ускорителями H100.

Источник изображения: Nvidia
По словам Nvidia, в настоящее время шесть коммерческих космических компаний используют её платформы в орбитальной и наземной средах: Aetherflux, Axiom Space, Kepler Communications, Planet Labs PBC, Sophia Space и Starcloud. При этом Kepler использует в своей спутниковой группировке платформу Jetson Orin для управления данными с помощью ИИ. «Nvidia Jetson Orin внедряет передовые технологии ИИ непосредственно на наши спутники, позволяя нам интеллектуально управлять данными и маршрутизировать их по всей нашей группировке», — заявила Мина Митри (Mina Mitry), генеральный директор компании, в официальном пресс-релизе Nvidia.
В октябре прошлого года основатель Amazon и Blue Origin Джефф Безос (Jeff Bezos) предсказал, что орбитальные центры обработки данных гигаваттного уровня появятся через 10–20 лет. В качестве основных преимуществ таких платформ он назвал непрерывное солнечное электроснабжение и упрощённую систему охлаждения в космосе. Starcloud, один из шести партнёров Nvidia, уже строит, как он сам описывает, специально разработанные орбитальные центры обработки данных, предназначенные для выполнения задач обучения моделей ИИ и вывода данных на орбите.
«Космические вычисления, последний рубеж, уже здесь», — сказал Дженсен Хуанг, добавив, что «обработка данных с помощью ИИ в космических и наземных системах обеспечивает сбор данных в реальном времени, принятие решений и автономность, превращая орбитальные центры обработки данных в инструменты исследований, а космические аппараты — в системы с автономным управлением».
Глава Nvidia не сказал, когда космический модуль Vera Rubin станет доступен для развёртывания. Компания уже предлагает в качестве космических платформ IGX Thor, Jetson Orin и RTX Pro 6000 Blackwell Server Edition.
Meta✴ закупит миллионы ИИ-чипов у Nvidia, включая центральные Arm-процессоры Grace и Vera
Компания Meta✴✴ Platforms готова расширить свою вычислительную инфраструктуру ИИ путём закупки дополнительных объёмов компонентов Nvidia, которые будут включать как GPU нового поколения, так и целые стойки семейства Vera Rubin, равно как и центральные процессоры Nvidia Grace.

Источник изображения: Nvidia
Как поясняет CNBC, исторически Meta✴✴ в развитии своей ИИ-инфраструктуры отличалась всеядностью, закупая ускорители AMD и процессоры Google, а также разрабатывая собственные. Помимо вычислительных решений Nvidia, на новом этапе расширения своей облачной инфраструктуры Meta✴✴ готова использовать и сетевые решения этой марки. Кроме того, чипы Nvidia помогут ей реализовать ИИ-функции в мессенджере WhatsApp.
Новая сделка между компаниями подразумевает закупку миллионов чипов Nvidia для нужд Meta✴✴ Platforms. На каких условиях это будет сделано, не уточняется. В январе Meta✴✴ объявила о намерениях потратить до $135 млрд на развитие ИИ в текущем году. По мнению аналитиков Creative Strategies, в случае с новой сделкой речь идёт о десятках миллиардов долларов США. Новость об этой сделке вызвала рост курса акций Nvidia и Meta✴✴, а вот акции AMD упали в цене на 4 %.
Компоненты Nvidia компания Meta✴✴ уже использует в своей инфраструктуре не менее десяти лет, но никогда ранее она не приобретала у неё центральные процессоры в отдельности от специализированных модулей, где те обычно соседствуют с GPU. Представители Nvidia подтвердили, что Meta✴✴ станет первым клиентом, приступившим к масштабному использованию центральных процессоров Grace. Эти чипы больше заточены под агентские ИИ-нагрузки и работу с инференсом. В 2027 году Meta✴✴ планирует перейти на использование нового поколения процессоров Vera разработки Nvidia.
В общей сложности до 2028 года Meta✴✴ планирует направить на развитие вычислительных мощностей в США около $600 млрд. Из 30 центров обработки данных, запланированных Meta✴✴ к строительству в ближайшие годы, 26 будут расположены на территории США. Крупнейшими станут гигаваттный Prometheus в Огайо и 5-ГВт Hyperion в Луизиане. Коммутаторы Spectrum-X производства Nvidia также будут применяться Meta✴✴ в своей инфраструктуре, а ещё последняя внедрит технологии безопасности первой для развития функций ИИ в WhatsApp.
Новых GeForce RTX пока не будет, — а заодно Nvidia сократит выпуск существующих видеокарт на 30–40 %
Бум систем ИИ вызвал не только дефицит памяти, но и высокий спрос на ускорители вычислений Nvidia, поэтому для этой компании выгоднее сосредоточиться именно на последней категории продукции. Как отмечает The Information со ссылкой на собственные источники, впервые в своей новейшей истории Nvidia может пережить текущий год без анонса новых моделей игровых видеокарт.

Источник изображения: Nvidia
Существующие квоты на микросхемы памяти Nvidia намеревается использовать для комплектации востребованных и более прибыльных ускорителей вычислений. Долгое время Nvidia считалась поставщиком игровых решений, но на фоне бума ИИ её приоритеты могли измениться, даже если руководство публично будет настаивать на обратном. Некоторые источники даже сообщают, что и объёмы выпуска игровых видеокарт существующего поколения (GeForce RTX 50) сокращаются из-за дефицита памяти. Нехватка самих видеокарт уже вызвала рост розничных цен по всему миру.
Представители Nvidia прокомментировали эту публикацию The Information лишь дежурной фразой о том, что спрос на видеокарты GeForce RTX остаётся высоким, а доступность памяти ограничена. Поставки видеокарт данного семейства продолжаются, а с производителями памяти компания старается работать над улучшением ситуации с доступностью компонентов.
По неофициальным данным, первоначально Nvidia в этом году планировала представить обновлённое семейство видеокарт с условным обозначением Kicker, чьи характеристики незначительно бы превосходили GeForce RTX 50, и разработка нового семейства фактически завершена. В декабре руководство компании якобы заявило заинтересованным специалистам, что вывод Kicker на рынок отложен на неопределённый срок. Имеющуюся в условиях дефицита память решено было направить на удовлетворение спроса в серверном сегменте.
Скорее всего, анонс более серьёзно обновлённого семейства видеокарт GeForce RTX 60 с архитектурой Rubin, который был запланирован на конец следующего года, тоже будет сдвинут «вправо». В серверном сегменте ускорители с архитектурой Rubin уже выпускаются, они будут доступны клиентам Nvidia со второй половины текущего года. За первые девять месяцев прошлого фискального года игровая выручка компании составляла лишь 8 % от совокупной, хотя до выхода ChatGPT осенью 2022 года эта доля достигала 35 %. Кроме того, на ускорителях вычислений Nvidia зарабатывает гораздо больше (до 65 %), чем на игровых видеокартах в удельном измерении (лишь 40 %).
Samsung начнёт выпускать память типа HBM4 для Nvidia в следующем месяце
В первой половине этого месяца появлялась информация о том, что начало массового выпуска памяти типа HBM4 откладывается до конца первого квартала по причинам, связанным с компанией Nvidia. Эту неделю агентство Reuters начало с сообщения о готовности Samsung начать производство HBM4 в следующем месяце.

Источник изображения: Nvidia
Получать эти чипы предсказуемо будет Nvidia, поскольку они требуются для производства ускорителей вычислений семейства Rubin. В случае с предыдущими поколениями ускорителей Nvidia приоритетным поставщиком HBM оставалась SK hynix, но Samsung уже давно идёт к цели по превращению в серьёзного поставщика HBM4, желая наверстать упущенное и как минимум догнать конкурента. Каким будет объём первых партий HBM4 в исполнении Samsung, не уточняется.
Южнокорейское издание Korea Economic Daily сегодня сообщило, что память HBM4 в исполнении Samsung прошла квалификационные тесты Nvidia и AMD, а потому формально этот производитель имеет возможность начать её поставки первому из клиентов в следующем месяце. Первые образцы HBM4 были отправлены Samsung для тестирования в лабораториях Nvidia ещё в сентябре прошлого года. SK hynix в октябре сообщила, что завершила переговоры о поставках HBM на 2026 год с основными клиентами. Ради удовлетворения спроса на память данного семейства SK hynix со следующего месяца начнёт поставки кремниевых пластин для производства памяти на новое предприятие M15X в Южной Корее. Samsung и SK hynix отчитаются о результатах прошлого квартала в этот четверг, наверняка на мероприятиях по этому поводу что-то будет сказано в отношении сроков поставок HBM4. Глава Nvidia в начале этого месяца подтвердил, что производство чипов для ускорителей Vera Rubin уже началось. Соответственно, медлить с выпуском HBM4 для этой платформы особой нужды нет.
Поставки первых систем на ускорителях Nvidia Rubin стартуют в конце лета
В этом месяце глава и основатель Nvidia Дженсен Хуанг (Jensen Huang) продемонстрировал ускорители вычислений поколения Rubin, заявив о начале их массового производства. Между тем, серверная продукция обычно длительное время добирается до конечных пользователей, а потому и поставки систем на семейства Vera Rubin партнёры Nvidia собираются начать лишь к концу этого лета.

Источник изображения: Nvidia
Об этом сообщает Commercial Times со ссылкой на комментарии вице-президента тайваньского производителя серверного оборудования Quanta Computer Майка Янга (Mike Yang), которые тот сделал на прошлой неделе на праздничном корпоративном мероприятии. Гиганты облачных вычислений начнут получать соответствующие системы на базе ускорителей Nvidia Rubin в августе текущего года. На тот момент отгрузки не будут массовыми, а потому Quanta Computer и не рассчитывает на получение существенной выручки от поставок первых систем на базе Vera Rubin.
Основная часть клиентов компании, по словам её представителя, уже эксплуатирует системы поколения Grace Blackwell (GB200 и GB300), что при условии родства архитектур с Vera Rubin позволит им достаточно быстро и безболезненно обновить в случае необходимости аппаратную базу. В официальных документах Nvidia осенью прошлого года сроки производства Vera Rubin упоминались достаточно размыто — под его начало отводился весь 2026 год.
Китайские разработчики признают, что для прогресса в сфере ИИ им нужен доступ к новейшим ускорителям Nvidia Rubin
Соперничество между США и КНР в сфере искусственного интеллекта перешло в открытую форму, прогресс каждой из сторон можно оценивать по разным критериям, но представители китайской отрасли признают, что обогнать США в ближайшие годы им не удастся. Тем более, что китайские разработчики даже не пытаются скрывать свою заинтересованность в доступе к американским ускорителям нового поколения.

Источник изображения: Nvidia
В прошлом месяце Дональд Трамп (Donald Trump) дал принципиальное согласие на организацию поставок в Китай ускорителей Nvidia H200, которые являются самыми производительными из доступных китайским разработчикам по официальным каналам. Пока китайские чиновники думают, на каких условиях разрешить импорт H200 в страну, представители местной ИИ-отрасли не скрывают своей заинтересованности в получении доступа к новейшим ускорителям типа Nvidia Rubin, которые остаются под американскими санкциями. Кстати, работа китайских компаний в режиме аренды вычислительных мощностей на базе Rubin за пределами страны формально сейчас не запрещена, поэтому хотя бы отчасти свои потребности китайские разработчики смогут покрыть. Впрочем, наличие такой лазейки для обхода санкций некоторые американские законодатели пытаются устранить.
Хотя глава Nvidia Дженсен Хуанг (Jensen Huang) и заявил, что спрос на H200 в Китае довольно высок, опрошенные The Wall Street Journal представители отрасли признались, что эти ускорители с архитектурой Hopper, отстающие от Rubin на два поколения, не пригодны для эффективного обучения передовых ИИ-моделей. Отчасти подобная оценка подкрепляется и настойчивыми слухами о том, что DeepSeek свои передовые модели обучала тайно на ускорителях Nvidia поколения Blackwell, и даже задержала выход новой версии своей языковой модели, поняв, что на отечественной компонентной базе достичь необходимых показателей не сможет. В будущем глава Nvidia готов наладить поставки в Китай ускорителей не только поколения Blackwell, но и более современного Rubin, но для этого они должны прилично устареть по меркам американского рынка. Интерес китайских разработчиков к ускорителям Blackwell уже начали изучать и китайские чиновники.
Китайские разработчики также подчёркивают, что доступных им вычислительных ресурсов в условиях бурного развития ИИ хватает преимущественно для поддержания работоспособности существующих ИИ-моделей, а для активной разработки новых их уже недостаточно. Все ресурсы фактически уходят на удовлетворение текущего спроса, а на исследования их уже не остаётся. По оценкам аналитиков UBS, в прошлом году китайские интернет-гиганты потратили на развитие своей вычислительной инфраструктуры только $57 млрд, что в десять раз меньше, чем у американских соперников.
Исследователи Epoch AI считают, что новейшие языковые модели Alibaba и DeepSeek от американских аналогов отстают от силы на четыре месяца, хотя ещё недавно отставание измерялось как минимум семью месяцами. Руководитель DeepMind на днях заявил, что для китайских конкурентов главной проблемой является отсутствие прорывных исследований, которые позволили бы обеспечить превосходство над ИИ западной разработки. Нехватка вычислительных мощностей, стало быть, является лишь одним из препятствий на пути к получению преимущества над американскими разработчиками.
Обнаружен самый «вёрткий» астероид Солнечной системы — он совершает оборот менее чем за две минуты
В своей массе астероиды — это куча щебня, сбившегося вместе под действием гравитации. Это наглядно показал таран зондом-камикадзе NASA DART астероида Диморф — после удара тот выбросил массу пыли и мелких камней. Это также означает, что астероидам не свойственно быстрое вращение вокруг своей оси — центробежная сила разорвёт их на мелкие части. Тем ценнее найти астероид со сверхвысокой скоростью вращения, что стало возможным с появлением нового телескопа.

Источник изображения: Vera C. Rubin Observatory
Открытие сделала Обсерватория имени Веры С. Рубин (Vera C. Rubin Observatory). Огромная 3,2-гигапиксельной камера LSST обсерватории размером 3 × 1,65 метра способна делать снимки больших участков неба каждые 40 секунд. С апреля по июнь 2025 года обсерватория проходила стадию настройки оборудования, что не помешало сделать множество интересных открытий даже до начала научной работы. Одним из таких открытий стало обнаружение самого быстро вращающегося астероида Солнечной системы в категории свыше 500 метров, который при своих размерах в 710 метров совершал полный оборот вокруг своей оси за 1,88 минуты.
Всего в процессе настройки оборудования Обсерватория «Рубин» открыла 1900 новых астероидов, 16 из которых могли похвастаться сверхбыстрым вращением, а 3 — ультрабыстрым, один из которых стал рекордсменом — это объект 2025 MN45. Три самых «вёртких» астероида совершали полный оборот менее чем за 5 минут, а 16 сверхбыстрых совершали обороты от 13 минут до 2,2 часа.

Отметка 2,2 часа на каждый оборот считается границей, ниже которой не монолитные астероиды разрываются центробежной силой. Тем самым все быстро вращающиеся астероиды состоят из плотной и даже монолитной породы. Большинство из впервые открытых астероидов расположены в Главном поясе астероидов между Марсом и Юпитером. После начала научной работы Обсерватории «Рубин» будут открыты сотни тысяч таких объектов. Ожидается, что работа обсерватории начнётся в ближайшие месяцы.
Дженсен Хуанг обвалил акции производителей систем охлаждения, просто рассказав об умеренных аппетитах Rubin
На мероприятии CES 2026 глава и основатель Nvidia Дженсен Хуанг (Jensen Huang) не только продемонстрировал образцы ускорителей поколения Rubin и подтвердил, что их выпуск уже налажен, но и сделал важное заявление относительно уровня тепловыделения этих решений. По его словам, для серверов на базе Rubin мощное жидкостное охлаждение не потребуется.

Что характерно, речь шла именно о так называемых «чиллерах» — устройствах, охлаждающих жидкость до околонулевых температур, которые исторически применялись в аквариумах и сфере экстремального разгона компьютерных компонентов. По сути, охлаждающая жидкость, пропускаемая через традиционные водоблоки, в таких системах дополнительно проходит через холодильные установки с фреоном. Это позволяет поддерживать низкие температуры в районе эксплуатируемых чипов на протяжении длительного времени.
Вот что буквально сказал Дженсен Хуанг про требования к охлаждению серверных систем на базе Rubin: «Центры обработки данных не потребуют использования водяных чиллеров». Как поясняет Reuters, такие заявления главы Nvidia вызвали падение котировок акций многих производителей систем охлаждения для серверного оборудования. Например, акции Johnson Control International потеряли в цене 7,5 %, а ценные бумаги Trane Technologies подешевели на 5,3 %. Акции обоих эмитентов оказались на уровне многомесячных минимумов и демонстрировали сильнейшую отрицательную динамику в составе индекса S&P 500. В структуре продаж этих компаний заказы для серверного сегмента формируют до 10 % или чуть более всей выручки.
Аналитики Barclays считают, что некоторые производители систем охлаждения при сложившейся конъюнктуре рынка выиграют от концентрации партнёров Nvidia на традиционных видах охлаждения серверных решений. Например, nVent Electric чиллеры не выпускает, но предлагает достаточно широкий ассортимент традиционных систем жидкостного охлаждения. Аналогичные выгодные позиции занимает на рынке Vertiv Holdings. Акции первой из компаний выросли в цене на 0,5 %, тогда как акции второй просели в цене на 2,1 %.
Ускорители Blackwell и Rubin появятся в Китае в своё время, как уверен глава Nvidia
Возможность поставлять ускорители вычислений H200 с архитектурой Hopper в Китай появилась у Nvidia под конец прошлого года благодаря личным усилиям основателя компании Дженсена Хуанга (Jensen Huang), и на CES 2026 он выразил уверенность, что в определённый момент до Китая доберутся и более совершенные ускорители с архитектурой Blackwell и Rubin.

Источник изображения: Nvidia
«H200 сейчас конкурентоспособен на рынке. Он не будет конкурентоспособен вечно», — пояснил на CES 2026 генеральный директор компании Дженсен Хуанг, говоря о позиционировании актуальных решений Nvidia в Китае. Для поддержания конкурентоспособности своей продукции в КНР, компания будет вынуждена со временем вывести на местный рынок решения с архитектурой Blackwell и Rubin, как он добавил. При этом правила США в отношении экспортного контроля должны будут эволюционировать, если Вашингтон желает поддерживать конкурентоспособность американских технологий на мировом рынке, как считает Хуанг.
Он также пояснил, что количество китайских стартапов, возникших в соответствующей сфере, а также их успешный выход на биржу, сами по себе говорят о темпах развития и промышленном потенциале Китая. По мнению Хуанга, китайский рынок технологий и дальше будет активно развиваться, поэтому для сохранения конкурентных позиций на нём Nvidia должна будет совершенствовать собственные технологии, предлагаемые местным клиентам. Новые продукты Nvidia в Китае продолжат «своевременно появляться», как резюмировал он.
В ожидании экспортных лицензий от властей США, которые позволят Nvidia наладить поставки ускорителей H200 в Китай, компания нарастила объёмы выпуска соответствующей продукции. Спрос со стороны китайских клиентов очень высок, как заверил глава Nvidia. Компания надеется, что вскоре сможет получить необходимые разрешения в США и наладить поставки H200 в Китай. По словам Хуанга, рассчитывать на публичное признание китайских властей в готовности разрешить поставки H200 на местный рынок не приходится. Маркером в этой сфере будут служить начавшиеся закупки со стороны китайских клиентов компании. Они не обязательно будут сопровождаться громкими публичными заявлениями.
Дженсен Хуанг показал ускорители Rubin на CES 2026 — их массовое производство уже запущено
Вполне предсказуемо, что основатель и генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) трибуну CES 2026 использовал не только для рассказа о новейших продуктах и технологиях компании, но и для убеждения инвесторов в том, что ИИ-пузырь далёк от схлопывания. Одним из аргументов стала демонстрация образцов ускорителей с архитектурой Rubin.

Источник изображения: Nikkei Asian Review
Они выйдут на рынок в этом году, во второй его половине, но глава Nvidia подчеркнул, что их производство уже идёт полным ходом. Архитектура Rubin является преемником весьма успешной Blackwell, и Nvidia не скрывает, что связывает с ней особые надежды. Отвечая на вопросы аудитории на CES 2026, основатель компании пояснил: «Мы попытаемся наращивать поставки изо всех сил. Во втором полугодии мы будет продавать много, поставлять много (ускорителей Rubin)». По сравнению с Blackwell, ускорители Rubin обеспечат рост производительности в инференсе в пять раз, а также в три с половиной раза в обучении языковых моделей. В обеих сферах удельная стоимость генерируемого токена сократится в десять раз по сравнению с Blackwell, поэтому разработчикам будет выгодно переходить на Rubin даже в том случае, если новые ускорители окажутся заметно дороже старых.

Источник изображения: Nvidia
Непосредственно графические процессоры поколения Rubin станут первыми продуктами Nvidia с памятью типа HBM4, которая обеспечит скорость передачи информации до 22 терабайт в секунду. Одними из первых клиентов Nvidia, получивших ускорители Rubin во втором полугодии, станут облачные провайдеры CoreWeave и Microsoft Azure. Образцы ускорителей Rubin уже вовсю тестируются клиентами Nvidia.
В одной серверной стойке могут объединяться до 72 графических процессоров Rubin и 36 центральных процессоров Vera. В одном вычислительном кластере могут объединяться до 1000 чипов Rubin, эффективность обмена данными между ними будет во многом определяться новыми сетевыми интерфейсами, которые были представлены параллельно. При работе в инференсе с форматом данных NVFP4, который Nvidia будет продвигать, ускорители Rubin обеспечивают быстродействие на уровне 50 петафлопс. Кратное повышение производительности и эффективности вычислений по сравнению с Blackwell было достигнуто при всего лишь 1,6-кратном увеличении количества транзисторов на чипе.
Игровые видеокарты теперь приносят всего 7,5 % выручки Nvidia — ИИ-чипы разогнали доходы до $57 млрд
Отчётность Nvidia за минувший фискальный квартал смогла порадовать тех инвесторов, которые ждали косвенных подтверждений сохранения высокого спроса компоненты для инфраструктуры ИИ. По итогам прошлого квартала выручка компании составила рекордные $57 млрд, увеличившись в годовом сравнении на 62 %, а последовательно сразу на 22 % или $10 млрд.

Источник изображений: Nvidia
Как отметила на мероприятии финансовый директор Nvidia Колетт Кресс (Colette Kress), компания рассчитывает выручить от реализации ускорителей семейств Blackwell и Rubin в размере $500 млрд за период с начала текущего года до конца 2026 календарного года. Спрос на компоненты для инфраструктуры ИИ продолжает превышать собственные ожидания Nvidia, по словам Колетт Кресс. Уже эксплуатируемые в составе облачных систем ускорители поколений Ampere, Hopper и Blackwell полностью загружены вычислениями.
В серверном сегменте выручка Nvidia в прошлом квартале выросла на 66 % в годовом сравнении до рекордных $51,2 млрд. Направление сетевых решений увеличило выручку сразу на 162 % до $8,2 млрд, что позволяет профильному бизнесу считаться крупнейшим в мире. В структуре ускорителей Blackwell произошло важное изменение: более современные GB300 начали доминировать над GB200 и формировать до двух третей всей выручки в семействе. Даже в условиях весьма серьёзных геополитических противоречий между Китаем и США компании удалось выручить за квартал на китайском рынке $50 млн от реализации ускорителей H20, хотя в конце прошлого квартала Nvidia не хотела публиковать подобную статистику в целом. Так или иначе, руководство компании утверждает, что продажи H20 не оказали существенного влияния на итоги квартала.
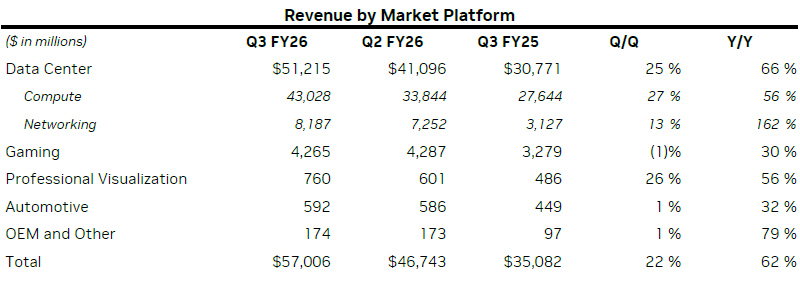
Игровой сегмент показал рост выручки на 30 % в годовом сравнении до $4,3 млрд (всего 7,5 % от всей выручки), но последовательно она снизилась на 1 %. Такая коррекция, по словам финансового директора Nvidia, обусловлена выходом складских запасов на более близкий к норме уровень в ожидании сезона предпраздничных распродаж. В годовом сравнении игровая выручка выросла преимущественно за счёт высокой популярности семейства Blackwell.
В сфере профессиональных решений для визуализации семейство Blackwell также показало себя с лучшей стороны, способствуя росту выручки на 56 % год к году до $760 млн, но в этом контексте упоминается и положительное влияние DGX Spark. Выручка Nvidia в автомобильном сегменте ограничилась $592 млн, но она выросла на 32 % в годовом сравнении и на 1 % последовательно. Наконец, сегмент OEM-решений и прочих источников дохода позволил Nvidia увеличить выручку на 79 % до $174 млн в годовом сравнении, хотя последовательный рост тоже ограничился 1 %.
В общей сложности, вычислительные и сетевые решения увеличили квартальную выручку Nvidia на 64 % до $50,9 млрд, тогда как на долю графических решений как таковых осталось только $6,1 млрд выручки. Тем не менее, и она в годовом сравнении увеличилась на 51 %. Руководство компании считает, что ежегодно в мире будет тратиться от $3 до $4 трлн на создание инфраструктуры для ИИ.
В части сроков анонса новых ускорителей с архитектурой Rubin финансовый директор Nvidia повторила, что они выйдут во второй половине 2026 года. Платформа Vera Rubin, сформированная из 7 чипов, способна обеспечить кратное увеличение быстродействия по сравнению с Blackwell.
В текущем квартале Nvidia рассчитывает выручить около $65 млрд, это подразумевает последовательный рост выручки на 14 %, во многом обусловленный высоким спросом на компоненты с архитектурой Blackwell. Если в прошлом квартале норма выручки компании составила 73,4 %, то в текущем она расположится в районе 74,8 %. В следующем году расходы компании вырастут, но Nvidia постарается поддерживать норму прибыли на уровне 74–76 %, по словам Кресс. На получение значимой выручки в Китае компания в текущем квартале тоже не рассчитывает.
Nvidia построит в США семь эксафлопсных суперкомпьютеров — два на Vera Rubin для Лос-Аламосской лаборатории
На конференции GTC 2025 компания Nvidia объявила о том, что построит в США семь эксафлопсных суперкомпьютеров в США. Две системы будут построены совместно с Oracle и будут использовать более 100 000 чипов Blackwell с производительностью до 2200 Эфлопс. Ещё две системы будут созданы совместно с HPE на перспективной платформе Vera Rubin для Лос-Аламосской национальной лаборатории.

Источник изображения: Nvidia
Эти системы будут использоваться для обеспечения национальной безопасности и проведения научных исследований с применением ИИ-моделирования и высокопроизводительных вычислений. Что интересно, заявление Nvidia последовало за вчерашним объявлением AMD о победе в тендерах на поставку пары суперкомпьютеров для Министерства энергетики США.
Лос-Аламосская национальная лаборатория заключила контракт с HPE на создание суперкомпьютеров Mission и Vision на базе платформы Vera Rubin от Nvidia, которая включает центральные процессоры Vera и графические процессоры Rubin нового поколения. Масштабирование машин будет осуществляться с помощью технологии NVLink Gen6, а горизонтальное — посредством сетевого интерфейса Nvidia QuantumX 800 Infiniband.
Суперкомпьютер Mission, разработанный для Национального управления по ядерной безопасности, планируется ввести в эксплуатацию в 2027 году. Компьютер Vision будет опираться на достижения предыдущего суперкомпьютера Venado и использоваться для открытых научных исследований, включая исследования в области искусственного интеллекта.
«Mission — пятая передовая технологическая система в рамках программы Лос-Аламоса по развитию искусственного интеллекта для научной безопасности. Ожидается, что она будет введена в эксплуатацию в 2027 году и предназначена для запуска секретных приложений. Система Vision основана на достижениях суперкомпьютера Venado из LANL и предназначена для несекретных исследований в области искусственного интеллекта и открытой науки. Системы Mission и Vision представляют собой значительные инвестиции в национальную безопасность США и развитие открытых научных возможностей», — заявил Дион Харрис (Dion Harris), руководитель отдела маркетинга продуктов центров обработки данных Nvidia.
Nvidia не раскрыла ожидаемую производительность Mission и Vision. Однако Vision примет эстафету у Venado — 19-го по скорости суперкомпьютера в мире с производительностью Rmax FP64 98,51 Пфлопс. Поэтому вполне логично ожидать, что Vision обеспечит как минимум вдвое большую вычислительную мощность для научных задач.
«Мы предоставим более подробную информацию о конкретных конфигурациях [суперкомпьютеров] позже. Самое замечательное в этой [платформе], учитывая, как эти системы будут использоваться как в открытой науке, так и в исследованиях в области национальной безопасности, заключается в том, что, по нашему мнению, она позволит использовать как возможности ИИ, так и традиционные возможности моделирования для научных исследований», — добавил Харрис.